


说点什么吧~
原帖子
http://mooc.guokr.com/note/21164/
微软亚洲研究院大数据系列讲座
What is Big Data
A new generation of technologies and architectures designed to economically extract value from very large volumes of a wide variety of data by enabling high-velocity capture,discovery,and/or analysis.——IDC
Big data is high-volume,high-velocity and high-variety information assets that demand cost-effective,innovative forms of information processing for enhanced insight and decision making.——Gardner

“大数据”的经典定义是可以归纳为5个V:海量的数据规模(volume)、快速的数据流转和动态的数据体系(velocity)、多样的数据类型(variety)和巨大的数据价值(value)、还有一个没记到。
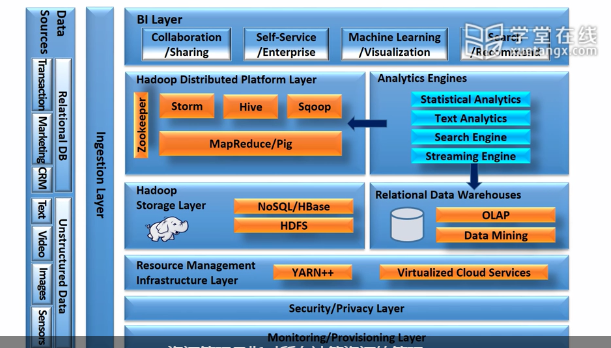
可以用两种方式来看基础设施。可以从非常非常底层来看, 需要一些可以监控的东西。 需要能够流畅地运行任何云计算。 需要一些东西来监控,保证每件事情都运行良好。 当有一些东西、一些任务时,你们需要自动配置(provisioning)。 你们需要知道你们需要多少存储和节点计算。 自动配置是指谁能看到数据,谁会真正运行程序。 这是基本管理层。 然后,在基本管理层之上,你需要建立安全和隐私层。 然后你需要考虑认证、用户账号、数据账号。 实际上,这可能会非常复杂,因为 在物联网中, 不仅有用户账号,还有机器账号。 谁能够给你发送数据? 例如,就像每隔15秒检测一次温度的环境传感器。 不仅是用户账号,你也需要机器账号。 你需要允许传感器向我发送数据。 因为,请记住,数据量可能是巨大的。 它们会在几个小时之内向你发送几个TB或者几个PB的数据, 就好像传统的拒绝服务攻击DoS一样。 人们可以对你进行恶意攻击。 但是我们并不是在谈论恶意攻击。 如有有一个未注册的传感器想要给你发送很多数据, 如果你不拒绝,你想要接收,那么就会有成本。 因此,你需要对其进行管理。这就是我们所说的安全隐私层。 也包括谁能够访问数据。 在安全隐私层之上有Hadoop和YARN。 在微软,我们称之为YARN++,它管理所有的资源。 所有计算资源,所有存储资源, 所有工作负载的资源,等等。 资源管理是指对所有计算资源的管理。 在资源管理之上,你通常会看到两个部分。 一个是传统的关系型数据库、数据仓库, 在这里你看到了SQL,你使用其他数据库。 另一个就是Hadoop、MapReduce、HDFS, 它们主要处理非结构化数据, 这就是为什么你们看左边的数据源, 你们有传统的结构化和非结构化数据会经过吸取层, 非结构化数据进入Hadoop一侧,结构化数据进入数据库一侧。 在Apache Hadoop平台层, 有很多很多像HBase这样的东西,类似Big Table, 然后你还有NoSQL。NoSQL不是说没有SQL。 NoSQL的意思是Not Only SQL, 谈到现在的数据库,不是传统的表格数据库。 然后是Hive,你的查询系统。 考虑传统的结构化数据库, 实际上你需要在Hadoop的非结构化存储中有一个对应的功能。 因此对于查询处理和查询优化,你们有Hive。 一个能实时处理很大数据量的流, 能够高效计算,你们有Storm。 你们还有Sqoop, 你们在结构化数据和非结构化数据之间移动大块数据。 你们有Zookeeper来处理所有协调性的工作。 你们还有Pig脚本语言,它是一个比MapReduce更高层的语言。 然后你们还有这个更高层的分析引擎, 不需要考虑它是来自非结构化的部分 还是结构化的部分。 你们可以做统计分析,像SAS文本分析。 然后你们还可以有基本的搜索引擎。 搜索基本上就是当你有一个查询请求给搜索引擎时,你希望实际上 提取你想要看到的任何模式。 然后在这些之上,大部分是给开发人员提供的 用来真正建立协作和分享工具、 自服务应用,或者机器学习可视化等。 所以,这就是完整的基础设施图。
当你实际上提到, 特别是对想要提供组件和工具的人, 来进行大数据分析, 以及对应用开发者,。 知道你会在哪一层也很重要。 你所在的层越高,你的编程环境就越容易。 但是,高层很有可能不允许你接触很多原始数据, 以及一些底层的东西。 但是,如果你到了一个更低的层, 你就可以做更多大规模计算和功能, 但是你也需要学习更多有关底层的东西。 这就是你应该如何思考这个架构。
现在,来说说这个模型和大数据。 在某种意义上,我认为科学家一直在这样做, 他们观察世界,记录数据, 知道A正比于某个事物的平方或者反比于某个事物的平方。 知道A正比于B,我可以列出一个公式 A = kB, k是常数。 在某种意义上,他们在处理那个时代的大数据,然而数据量并不是很大。 但是他们不得不观察,否则你怎样才能重复这个呢? 这不是你写一个规则。你需要匹配世界。 所以,理论物理总是需要实验物理来验证, 然后得出最终的规则来描述世界。 所以,在科学世界,这就像创造一个世界的模型, 做实验或者进行观察来获得数据。 然后验证模型的正确性, 将模型应用到新的场景中。 如果这足够好,很棒,那就是你要使用的模型, 可以广泛地使用它了。 对于另一个物理或者另一个人类行为, 就像我提到的语言,你也需要收集这些例外, 写出新的规则,或者就称之为例外。 在微软,我们在几年之前还出版了一本书, 实际上我们的想法来自于吉姆, 他是数据库领域的伟大先驱。
下面谈谈第四个范式。在科学世界。 第一范式,实证科学,通过观察。 我的意思是,通过观察得到的数据并不是很大。 数据肯定是在一个更原始的形式, 而不是质量很高、数量很大的形式。 下面是理论科学, 使用理论和概括,也是基于实证的东西, 但是已经有了一些更精细的数据, 来真正地描述这个世界。 第三个范式是计算科学, 做很多模拟,甚至是 使用计算来研究数学和物理这类现象。 第四个范式实际上是由吉姆.格雷提出来的。 他预见了这个大数据时代, 在所有的科学领域使用数据。 大数据已经提供了机会 去把所有的理论、实验和模拟统一在一起。 大数据不仅给你们提供了 以更精细的方式做大规模实验来验证你们的模型的能力, 而且给你们提供了连续监控的能力, 而且帮助你们在真实世界来做这些事情,我甚至不称之为模拟。 而是在真实世界中做的验证,来真正地看现象。 这是真的,非常棒,你们能够发表科学工作, 但是另一件事情是,甚至是自然的,规则将漂移到一些不同到东西。 因此在机器学习社区里就有了在线学习和主动学习, 他们能够帮助你演化模型。 社会网络就是一个非常好的例子, 人们会改变,一代一代的人也会改变。 如果你想要确定一些规则来描述一些现象, 这几乎是不可能的。 然后,第四个维度使用大数据, 把我们知道的所有事情结合在一起——我们不会扔掉那些东西。 特别是,如果有这样简单的规则来描述世界的话, 没有人会真正放弃 公式不可思议的有效性之美。 但是,同时,这个世界也是非常复杂的, 我们有大数据来帮助我们来做所有这些东西。
现在,你们要发现新的理论变得越来越困难, 只有有限的理论等你发现。 但是,还有很多你们在过去不能做的事情, 现在有了所有这些基础设施,大数据允许我们去做, 甚至是以无所不在的方式做这些事情。 不只是自然科学、社会科学,各种各样的东西, 实际上你们可以做,甚至是以纯科学的方式。 然后我们讨论分析,以一种方式, 你可以思考这个——我想这不是压缩, 它不只是压缩,它是提取。 大数据转换,你获得很大量的数据, 你进行精炼,进行连接,然后进行融合。 最后你将获得我们所说的知识。 整个事情就是关于把一些东西变得越来越精炼, 最后获得一些有深刻洞见的东西, 然后你们采取行动。 你们看看整个数据循环, 人们可能说这是烦人的,但是相信我,这非常非常重要, 如果做不好,就像我所说的,错进错出。 所以,数据收集,你们如何做摄取、抽取、转换和加载 加载到大数据存储管理平台, 结构化的和非结构化的。 然后你可以开始做大数据分析和挖掘。 然后你可以建模和预测。 一旦你真正有了发现, 你可以公布你的发现,并把它可视化 并最终作为应用程序部署。 在某种意义上,现在,天气预报、PM 2.5预报, 不管是什么,在某种意义上都是大数据应用。 如果你想想人们如何预测数据, 预测天气,这本身就是一个大数据问题。 我们总是可以做得更好。


说点什么吧~
欢迎来到学堂在线广场~
在这里你可以玩活动,看资讯,晒笔记。
还可以交学友、发心情、聊人生。
在学堂的每一天,就从这里开始吧!
点击 广场指南 了解更多

